Appearance
Depth Anything V2 -- 導入・モデル比較・LKG表示
1. 概要
このセクションでは、Depth Anything V2 がどのようなモデルで、なぜ重要なのかを学びます。
Depth Anything V2(以下 DAV2)は、単眼深度推定(Monocular Depth Estimation) のためのモデルです(NeurIPS 2024 採択)。単眼深度推定とは、1枚の2D画像から各ピクセルの奥行き(depth)を推定する技術のことです。ステレオカメラやLiDARといった特殊なセンサーを使わず、通常のカメラで撮影した1枚の画像だけで3D的な情報を得られる点が大きな利点です。
DAV2 は内部に Vision Transformer(ViT) をエンコーダとして採用しています。ViT は画像を小さなパッチ(断片)に分割し、トランスフォーマーアーキテクチャで処理する手法で、従来の CNN ベースの手法と比較して画像全体の広い範囲の文脈を捉えることに優れています。デコーダには DPT(Dense Prediction Transformer) を使用し、高解像度の深度マップを出力します。
DAV2 の位置づけ -- 相対深度推定モデル
深度推定モデルには大きく2つのアプローチがあります。
- 相対深度推定(Relative Depth Estimation): ピクセル間の相対的な前後関係(どちらが手前か奥か)を推定します。深度値の単位は任意で、実際のメートル数は分かりません。DAV2 の標準モードはこちらに該当します。
- メトリック深度推定(Metric Depth Estimation): 実際の距離(メートル単位)を推定します。Apple Depth Pro などが該当します。
LKG(Looking Glass)ディスプレイで立体表示を行う際には深度マップが必要になりますが、相対深度推定で十分な場合が多いです。DAV2 は高精度な相対深度マップを高速に生成でき、LKG 用途に適しているため、ローカルPCに導入して検証を行いました。
他モデルとの比較
深度推定モデルには DAV2 以外にも複数の選択肢があります。各モデルの特徴を把握しておくと、用途に応じた使い分けができます。
- Apple Depth Pro: メトリック深度推定。実距離を出力するが、正規化の工夫が必要。→ Apple Depth Pro の記事
- MoGe(Microsoft): 深度マップだけでなく3Dメッシュ(GLB)を直接出力できる。→ MoGe の記事
- Marigold: 拡散モデルベースの深度推定。高品質だが推論速度はやや遅い。
- Video Depth Anything: DAV2 の動画対応版。フレーム間の一貫性を保った深度推定が可能。
2. 前提条件
このセクションでは、導入に必要な環境を確認します。
| 項目 | 要件 |
|---|---|
| OS | Windows 10/11 |
| Python | 3.10 以上(松崎の環境では Python 3.12) |
| GPU | CUDA対応 NVIDIA GPU |
| CUDA | 12.4 以上(xFormers利用時) |
| Git | インストール済み |
Python・Git・CUDA の基本的なインストール方法は 環境構築の入門ページ を参照してください。
推奨: 仮想環境で実行する
DAV2 の導入では PyTorch / xFormers / CUDA のバージョン競合が非常に起きやすいです(後述のトラブルシューティング参照)。Python 仮想環境(venv) を使えば、プロジェクトごとに依存関係を隔離でき、こうしたトラブルを大幅に軽減できます。問題が発生した場合は仮想環境ごと削除してやり直すことも容易です。
bash
# 仮想環境の作成
python -m venv .venv
# 仮想環境の有効化(Windows)
.venv\Scripts\activate
# 仮想環境の有効化(PowerShell)
.venv\Scripts\Activate.ps1
# 仮想環境内でパッケージをインストール
pip install -r requirements.txt
# 仮想環境の無効化
deactivate3. 導入手順
このセクションでは、リポジトリのクローンから深度マップ画像の出力まで、ステップバイステップで手順を学びます。
Step 1: リポジトリのクローン
作業するフォルダに移動してgitをcloneします。
bash
git clone https://github.com/DepthAnything/Depth-Anything-V2.git
cd ./Depth-Anything-V2Step 2: 依存パッケージのインストール
bash
pip install -r requirements.txtStep 3: チェックポイント(学習済みモデル)のダウンロード
checkpointsフォルダを作成し、GitHubリポジトリのREADMEからモデルをダウンロードします。
bash
mkdir checkpoints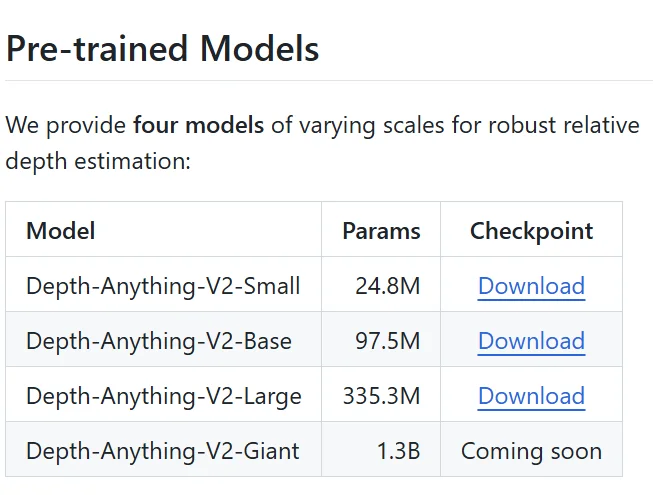
ダウンロードしたモデルファイル(.pth)をcheckpointsフォルダ直下に配置します。
DAV2 には複数のモデルサイズが用意されています。どのモデルをダウンロードすべきか迷う場合は、以下の表を参考にしてください。モデル名はエンコーダとして使われる ViT(Vision Transformer)のサイズに対応しています。
| モデル | エンコーダ名 | パラメータ数(概算) | 特徴 |
|---|---|---|---|
| Small | ViT-S (vits) | 約25M | 最も軽量。高速だが細部の精度は控えめ |
| Base | ViT-B (vitb) | 約97M | バランス型。多くの用途で十分な品質 |
| Large | ViT-L (vitl) | 約335M | 高精度。細部の奥行き表現が改善 |
| Giant | ViT-G (vitg) | 約1.0B | 最高精度。非常に大きく推論に時間がかかる |
松崎所感: 後述のモデル比較で詳しく述べるが、処理速度と品質のバランスを考慮すると Base または Large が実用的な選択肢である。特定の被写体(網のような細かい構造物)では Small の方が自然に見えるケースもあった。
Step 4: 推論スクリプトの作成
以下のコードをDepth-Anything-V2フォルダ直下にrun_depth.pyとして保存します。
python
import cv2
import torch
from depth_anything_v2.dpt import DepthAnythingV2
DEVICE = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
model_configs = {
'vits': {'encoder': 'vits', 'features': 64, 'out_channels': [48, 96, 192, 384]},
'vitb': {'encoder': 'vitb', 'features': 128, 'out_channels': [96, 192, 384, 768]},
'vitl': {'encoder': 'vitl', 'features': 256, 'out_channels': [256, 512, 1024, 1024]},
'vitg': {'encoder': 'vitg', 'features': 384, 'out_channels': [1536, 1536, 1536, 1536]}
}
encoder = 'vitb' # ダウンロードしたモデルに合わせて変更
model = DepthAnythingV2(**model_configs[encoder])
model.load_state_dict(torch.load(f'checkpoints/depth_anything_v2_{encoder}.pth', map_location='cpu'))
model = model.to(DEVICE).eval()
raw_img = cv2.imread('./data/Tom.jpg') # 推定したい画像のパスに変更
depth = model.infer_image(raw_img) # HxW raw depth map in numpyencoderの値はダウンロードした学習データに合わせて書き換えます:
- Smallモデルなら
"vits" - Baseモデルなら
"vitb" - Largeモデルなら
"vitl" - Giantモデルなら
"vitg"
Step 5: 画像出力つきの推論実行
上記のrun_depth.pyは深度推定は行いますが画像の出力まではしません。画像ファイルとして出力するには、リポジトリ付属のrun.pyを使用します。
bash
mkdir inputs outputsinputsフォルダに深度推定したい画像を入れて、以下を実行します。
bash
python run.py --encoder vitb --img-path inputs --outdir outputs/vitb/gray --pred-only --grayscale--encoder vitbとoutputs/vitb/grayの部分は、自分がダウンロードしたモデルに合わせて変更します。
outputsフォルダに深度推定した画像が出力されます。

4. トラブルシューティング
このセクションでは、Windows 環境での導入時に発生しやすいエラーとその原因・解決策を学びます。松崎が導入時に遭遇した問題とその解決策を整理したものであり、Windows 環境での DAV2 導入における貴重なノウハウが含まれています。
4.1 xFormersのインストール
xFormers は Transformer モデルの推論を高速化するライブラリで、DAV2 でも使用が推奨されます。ただし、Windows へのインストールには多くの落とし穴があります。
問題1: torch / torchaudio / torchvision のバージョン不整合
なぜ起きるか: pip は依存関係を解決する際、各パッケージの最新版を個別に取得しようとします。xFormers をインストールすると、その依存として最新の torch(例: 2.6.0)が引き込まれますが、既にインストール済みの torchaudio や torchvision は古い torch(例: 2.5.1)を要求しており、バージョンが噛み合わなくなります。PyTorch エコシステムでは torch / torchvision / torchaudio の3パッケージは厳密にバージョンが対応しているため、片方だけ上がると整合性が崩れます。
xformersをインストールした際にtorchが2.6.0にアップグレードされ、torchaudioとtorchvisionが要求するtorch 2.5.1との不整合が発生しました。
解決方法: バージョンを明示的に指定してインストールします。
bash
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1前のバージョンのtorchは自動的にuninstallされるため、手動でuninstallする必要はありません。
問題2: Windowsの長いパスエラー
なぜ起きるか: Windows には歴史的にファイルパスの長さが260文字までという制限(MAX_PATH 制限)があります。PyTorch や xFormers のパッケージには非常に長いファイル名を持つヘッダファイルが含まれており、pip がこれらを一時フォルダに展開する際にパスが260文字を超え、「ファイルが見つからない」というエラーになります。
xformersのインストール時に一時ファイルのパスが長すぎてエラーが出ます。Windowsではデフォルトで「長いパス」が無効になっているためです。
解決方法A: グループポリシーエディターで設定します。
Win + Rでgpedit.mscを開きます- コンピューターの構成 > 管理用テンプレート > システム > ファイルシステム の順に進みます
- 「長いパスを有効にする」をダブルクリックし、「有効」に設定します
- PCを再起動します

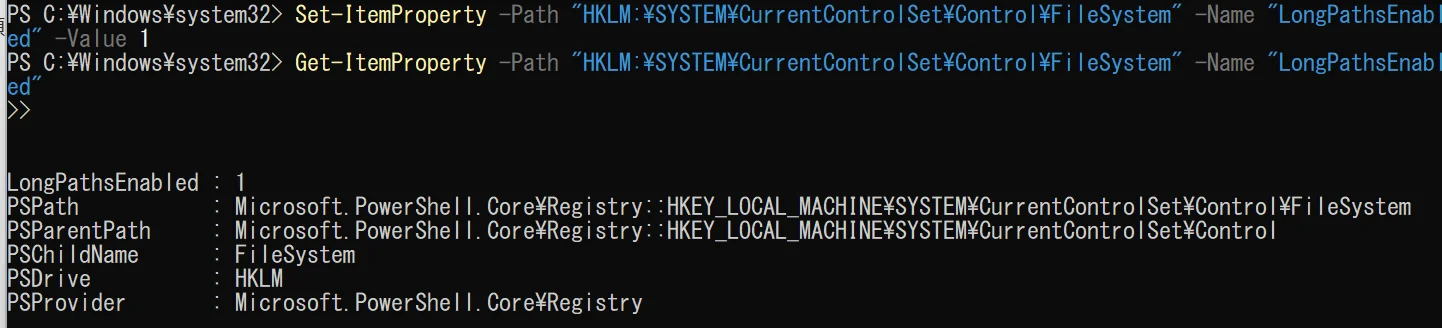
解決方法B: PowerShellで設定します(グループポリシーで有効にできなかった場合)。
PowerShellを管理者権限で開き、以下を実行します。
powershell
Set-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\FileSystem" -Name "LongPathsEnabled" -Value 1確認コマンド:
powershell
Get-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\FileSystem" -Name "LongPathsEnabled"LongPathsEnabled: 1 になっていれば成功です。再起動します。
問題3: xFormersインストール後のPyTorchバージョン競合
なぜ起きるか: 問題1と同じメカニズムです。xFormers のインストール時に pip が依存解決を行い、torch を再び最新版に上書きしてしまいます。pip の依存解決は「今インストールしようとしているパッケージの依存」を優先するため、既存パッケージとの整合性が崩れやすいです。
xformersをインストールすると、再びtorchが2.6.0に上書きされてしまいます。
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed.
torchaudio 2.5.1 requires torch==2.5.1, but you have torch 2.6.0 which is incompatible.
torchvision 0.20.1 requires torch==2.5.1, but you have torch 2.6.0 which is incompatible.
Successfully installed torch-2.6.0 xformers-0.0.29.post3解決方法: pytorch関連を全削除してから、バージョン指定で再インストールします。
bash
# 1. pytorch関連を全削除
pip uninstall torch torchvision torchaudio xformers
# 2. 指定のバージョンをインストールしなおす
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1
# 3. xformers を改めてインストール
pip install xformers==0.0.28問題4: ビルド時にtorchが見つからない
なぜ起きるか: pip にはビルド隔離(build isolation)という機能があります。パッケージをソースからビルドする際、pip は一時的にクリーンなビルド環境を作成します。この隔離された環境には、ユーザーが既にインストールした torch が含まれないため、xFormers のビルドプロセスが「torch が見つからない」とエラーを出します。
pip install xformers==0.0.28 で毎回torchが見つからないとエラーが出る場合があります。これはpipのビルド隔離(build isolation)機能が原因で、ビルド用の一時環境ではインストール済みのtorchが認識されません。
解決方法: --no-build-isolationオプションを付けてインストールします。
bash
pip install --no-build-isolation xformers==0.0.284.2 CUDAアップグレード
このセクションでは、CUDAバージョンの選定と、PyTorch との互換性について学びます。
xFormersのWindows対応はCUDA 12.4以上が必要です。松崎の環境はCUDA 11.8だったため、アップグレードが必要になりました。
なぜ CUDA バージョンが重要なのか
PyTorch の各バージョンは特定の CUDA バージョンに対応しています。組み合わせを間違えると GPU を認識できず、CPU での実行にフォールバックします(=非常に遅くなります)。以下の互換性マトリクスを参考にしてください。
| PyTorch | CUDA 11.8 | CUDA 12.1 | CUDA 12.4 | CUDA 12.6 |
|---|---|---|---|---|
| 2.4.x | cu118 | cu121 | -- | -- |
| 2.5.x | cu118 | cu121 | cu124 | -- |
| 2.6.x | cu118 | cu121 | cu124 | cu126 |
PyTorch のインストール時には --index-url で CUDA バージョンを指定することが重要です。公式のインストールコマンド生成ページ(https://pytorch.org/get-started/locally/)を活用すると確実です。
CUDA 11.8 から 12.6 への移行(失敗)
最初にCUDA 12.6をインストールしましたが、後述のTritonの問題で12.4に戻すことになりました。
注意: CUDAのダウンロードサイトで最新版(12.8など)を誤ってインストールしないよう注意。アーカイブから特定バージョンを選ぶこと。
最終的な構成: CUDA 12.4
インストール後の作業:
環境変数の設定:
CUDA_HOMEにCUDA 12.4のフォルダパスを追加し、CUDA_PATHが正しいパスになっているか確認しますPyTorchの再インストール(CUDA 12.4対応版):
bash
pip uninstall torch torchvision torchaudio xformers
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124- xFormersの再インストール(CUDA 12.4対応版):
bash
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu124インストール中のエラー対処: エラーが出た場合は、前バージョンのCUDAを
C:\Program Files\NVIDIA GPU Computing Toolkitから直接削除してからやり直す。
4.3 Triton(Windows)
なぜこの問題が起きるか: Triton は xFormers が内部で使用する GPU カーネルの最適化ライブラリです。Linux 向けには公式ビルドが提供されていますが、Windows 向けの公式ビルドは存在しません。そのため、有志がビルドしたバイナリを手動でインストールする必要があります。
有志によるWindows向けビルド: madbuda/triton-windows-builds (Hugging Face)
.whlファイルをダウンロードし、以下のようにインストールします。
bash
pip install C:\work\triton-3.0.0-cp312-cp312-win_amd64.whl
.whlファイルはPythonパッケージのバイナリ配布形式で、pip install パスでローカルからインストールできます。ダウンロード先は適切なフォルダに配置すること。

4.4 最終的な導入手順まとめ
上記のトラブルシューティングを踏まえた、最終的なクリーンインストール手順は以下の通りです:
- CUDA 12.4 をインストール
- 環境変数
CUDA_HOME/CUDA_PATHを設定 - Windowsの長いパスサポートを有効化
- リポジトリをクローン、requirements.txtをインストール
- PyTorch(CUDA 12.4対応版)をインストール
- xFormers(CUDA 12.4対応版)をインストール
- Triton(Windows有志ビルド)をインストール
- チェックポイントをダウンロード
run.pyで推論実行
5. モデル比較(LKGでの評価)
このセクションでは、モデルサイズによる出力品質と処理速度の違いを、LKG 表示での実際の評価結果から学びます。
Small / Base / Large の3モデルと、HuggingFace版を比較しました。LKG側のdepth設定はすべて一定にし、フォーカスは適宜合わせています。
処理速度
スマホのストップウォッチで手打ち測定のため参考値とします。
| モデル | 処理時間 |
|---|---|
| Small(vits) | 約3.4秒 |
| Base(vitb) | 約3.8秒 |
| Large(vitl) | 約7.4秒 |
学習データが大きくなるにつれて処理時間は長くなりました。
深度マップの比較画像
huggingface → Small → Base → Large の順に並べた比較画像:
.webp)



LKG表示での比較表
| モデル | トムとジェリー | ハト | バスケ | ポートレート |
|---|---|---|---|---|
| huggingface | あまりlargeと大差ない感じがする。 | 奥行きの上限値がbaseよりも下がっている印象。黒い金網の出力は baseと変わってない。 | baseより少し精度が落ちているかなという印象。網の出力はsmallより少し下手くらい。 | baseよりのっぺりしてるけどsmallほどではない。 |
| small | 一番トムの耳部分が、左耳が前、右耳が後ろという風に出力されている。その分顔のゆがみがひどい気もする。 | 上位モデルに比べて奥の黒い金網がのっぺりしている気がする | ボード部分の穴が一番小さい。網の出力は一番うまい。 | 頭の丸みが奥に行きすぎな感じがある。 |
| base | トムの横顔部分が奥に行き過ぎている。顔が斜めりすぎな感じがある。 | largeとはあまり差がないかもしれない。しいて言えば奥行き感がlargeより大きいかも。 | 中間くらい。網の出力は結び目部分が強調されている。 | smallに奥行きが足されてる。頭の丸みがsmallより違和感がない。ただ、頭頂部は平らっぽい。 |
| large | トムの手が一番前に出て見える。ほほのふくらみや、膝がこっちに出ているところなどしっかり出力されている。フォーカスが当たっている部分のぼやけが一番少ない。 | 背景までしっかり奥行きがついている。道路の奥行きもしっかり見えて、右側の電柱の丸みも出力されている。 | ボード部分の穴が一番大きい。ボールの丸みは上手く出力できているが、網の出力は結び目部分のみ強調されている感じがある。 | baseに出っ張りが足されてる。胸の描写が奥に斜めるようになってる。頭の頂点がうえ方向に丸みがついてるように見える |
| 補足 | 前景においては大差なかった。 | 顔の中心部分の出力は大差なかった。 |
福田さんとのレビューまとめ
福田さんに一緒にレビューしていただいた際の所見です:
- もし業務で使う際、実際の人を写すとき、largeだとアジア人にとっては目鼻立ちがくっきりしすぎるかもしれない。
- 全体的に変化が微弱すぎて好みの問題感はある。
- smallとlargeで比べたらlargeのほうがきれいな場合が多いが、バスケの写真だけは網の精度がsmallのほうがきれいに見えた。
松崎所感: モデルが大きいほど全体的な深度の精度は向上する傾向にあるが、特定の被写体(網のような細かい構造物)では Small モデルの方が自然に見えるケースもあった。LKG 表示用途では、処理速度と品質のバランスを考慮して Base または Large が実用的な選択肢となる。
6. LKGでの表示
このセクションでは、HuggingFace 版とローカル Base モデルの LKG 表示結果を比較し、ローカル導入の効果を確認します。
huggingface版 vs ローカルBaseモデル
SDS(Side-by-Side)画像を作成してLKGディスプレイで比較した結果です:




観察結果
- ほかモデルと同様、やはり網部分は苦手らしくぐちゃぐちゃになっています。ただし、huggingfaceで試した時よりかはましになっています。
- ハトにフォーカスを当てるとあまり違いが分かりませんが、奥の方にフォーカスを充てるとローカル版のほうが気持ち立体感がついています。
- 額や胸の遠近感が増しています。頭の丸みなどが表現できています。
- トムの顔の立体感の解像度がよくなっています。
- 変に奥行き感が間延びしている感じもあります(手の部分など)。
総評
全体的に立体感は付きやすくなったと思いますが、ついた立体感がきれいか、雑でないかという観点に関してはよいと言い切れない部分があります。
7. 参考リンク
公式
- Depth Anything V2 公式サイト
- GitHub - DepthAnything/Depth-Anything-V2
- 論文: Depth Anything V2 (arXiv)
- PyTorchインストール: https://pytorch.org/get-started/locally/
参考記事
- 単眼深度推定のアルゴリズム Depth-Anything を試す(Zenn)
- 深度推定モデル Deep Anything v2を試してみる(Qiita)
- Depth Anything V1とV2の結果を見比べる(note)
CUDA / ツール関連
- CUDA Toolkit 12.4 Downloads
- CUDA Toolkit 12.6 Downloads
- CUDA アップグレード手順(Qiita)
- Triton 3.0.0 for Windows(note)
- madbuda/triton-windows-builds(Hugging Face)
whlインストール関連
- Pythonパッケージをwhlファイルを使ってインストールする(Qiita)
- .whlファイルのインストールエラー対応(Qiita)
- ローカルの whl を使ってpip installする(Nishikoh Tech Blog)
関連する深度推定モデル
- Depth Anything V1: V2 の前バージョン。V2 は合成データを活用した学習手法の改善により、より高精度な深度推定を実現しています。
- Apple Depth Pro: Apple が開発したメトリック深度推定モデル。→ Apple Depth Pro の記事
- MoGe(Microsoft): 3D メッシュを直接出力できる深度推定モデル。→ MoGe の記事
- Marigold: 拡散モデルベースの深度推定。高品質だが推論速度はやや遅い。
- Video Depth Anything: DAV2 の動画対応版。フレーム間の一貫性を保った深度推定が可能。
- Distill Any Depth: 蒸留技術を用いた軽量な深度推定モデル。
Author: 松崎 | Source:
松崎\Depth Anything V2 1a6aba435ee780f3a853ca86111e453b.mdAI Enhanced: Claude -- 2026-03-05