Appearance
Apple Depth Pro -- メトリック深度推定と正規化手法
概要
このセクションでは、Apple Depth Pro の特徴と、他の深度推定モデルとの違いを学びます。
Apple Depth Pro(ml-depth-pro)は、Apple が公開した単眼深度推定モデルです。「Sharp Monocular Metric Depth in Less Than a Second」を掲げており、1枚のRGB画像からメトリック(実距離)スケールの深度マップを高速に生成できます。
推論速度は非常に速く、GPU環境で大体2秒以下で出力されます。立体感の付け方が丁寧で、無理に凹凸を強調しない自然な深度推定が特徴です。
Apple Depth Pro の位置づけ
Apple Depth Pro はメトリック深度推定モデルの代表格であり、Depth Anything V2 のような相対深度推定モデルとは根本的なアプローチが異なります。この違いを理解しておくことが、後述する正規化の問題を理解する上で重要です。
メトリック深度推定とは
このセクションでは、メトリック深度推定と相対深度推定の違いを理解し、Apple Depth Pro の出力特性を学びます。
深度推定モデルには大きく2つのアプローチがあります。
| 相対深度推定 | メトリック深度推定 | |
|---|---|---|
| 出力内容 | ピクセル間の前後関係(どちらが近いか遠いか) | 実際の距離(メートル単位) |
| 深度値の単位 | 任意(相対的) | メートル |
| 代表的なモデル | Depth Anything V2、MiDaS | Apple Depth Pro |
| 正規化の手間 | 少ない(値の範囲が安定) | 多い(画像内容により値の範囲が大きく変動) |
Apple Depth Pro は ViT(Vision Transformer)ベースのエンコーダと多スケールデコーダを組み合わせ、焦点距離の推定も同時に行います。これにより、カメラ内部パラメータが不明な画像に対してもメトリック深度を推定できます。
重要な特性: メトリック深度推定では出力値が実距離を反映するため、屋外画像の遠景ピクセルは非常に大きな深度値(例: 10000.0)を持つことがあります。この性質が後述する「屋外画像が真っ黒になる問題」に直結します。
検証用画像
以下の4枚の画像を使って検証を行いました。




前提条件
このセクションでは、導入に必要な環境を確認します。
| 項目 | 要件 |
|---|---|
| Python | 3.x(venv対応バージョン) |
| GPU | CUDA対応NVIDIA GPU |
| CUDA | 11.8以上推奨 |
| Git | リポジトリクローン用 |
| OS | Windows(コマンドプロンプト使用) |
Python・Git・CUDA の基本的なインストール方法は 環境構築の入門ページ を参照してください。
導入手順
このセクションでは、仮想環境の構築からモデルの実行までを学びます。
試行手順は上記Qiitaの通りです。
注意
コマンドプロンプトに途中にあるコマンド群を一気にコピペすると動かない。一行ずつコピペして実行すること。
作業するフォルダでコマンドプロンプトを起動し、以下のコマンドを実行します。
bash
# 仮想環境作成
python -m venv depthpro_env
# 仮想環境アクティベイト
depthpro_env\Scripts\activate
# フォルダ移動
cd depthpro_env
# gitクローン
git clone https://github.com/apple/ml-depth-pro.git
# フォルダ移動
cd ml-depth-pro
# ライブラリインストール
pip install -e .
# モデルを配置するフォルダを作成する
mkdir checkpointscheckpointsフォルダにgitからダウンロードしたファイルを配置します。
pytorchのインストール(cpuのpytorchをアンインストール)
bash
pip uninstall torch torchvision torchaudiopytorchのCUDA版のインストール(以下CUDA11.8のコマンド)
bash
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118メモ
仮想環境を一回閉じたらもう一回環境構築し直す必要がある可能性がある。仮想環境のactivateは毎回必要。
深度マップの出力
このセクションでは、深度マップを画像として出力するスクリプトの作成と実行を学びます。
基本スクリプト(generate_depth_map.py)
ml-depth-proフォルダで以下のプログラムを作成します。
python
import torch
import numpy as np
from PIL import Image
import depth_pro
def generate_depth_map(input_path, output_path):
# GPUが利用可能な場合はGPUを使用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# モデルとトランスフォームの読み込み
model, transform = depth_pro.create_model_and_transforms()
model = model.to(device)
model.eval()
# 画像の読み込みと前処理
image, _, f_px = depth_pro.load_rgb(input_path)
image = transform(image).unsqueeze(0).to(device)
# 推論の実行
with torch.no_grad():
prediction = model.infer(image, f_px=f_px)
# デプスマップの取得
depth = prediction["depth"].squeeze().cpu().numpy()
# デプスマップの正規化 (0-255の範囲に)
depth_normalized = ((depth - depth.min()) / (depth.max() - depth.min()) * 255).astype(np.uint8)
# デプスマップをグレースケール画像として保存
depth_image = Image.fromarray(depth_normalized)
depth_image.save(output_path)
print(f"Depth map saved to {output_path}")
if __name__ == "__main__":
input_image_path = "./data/example.jpg" # 入力画像のパスを指定
output_image_path = "./depth_map_output.png" # 出力画像のパスを指定
generate_depth_map(input_image_path, output_image_path)入力画像を用意して、フォルダに入れておき、そこのパスをコード内で指定することを忘れずに。
ここまででおそらくml-depth-proフォルダが二重構造になっているのがコマンドプロンプトからわかると思うので(以下参照)

cd .. で階層をml-depth-proまでさかのぼります。
以下で実行します。
bash
python generate_depth_map.py以下画像がml-depth-proフォルダ直下に出力されます。

(これ、depthの最大値と最小値がおかしくなっているみたいです。)
デモ実行(Figure1アプリ)
Qiitaの手順通りに実行するとFigure1というアプリが開いて、以下のような画面になります。左下の保存ボタンから画像が保存できます。
出力結果:
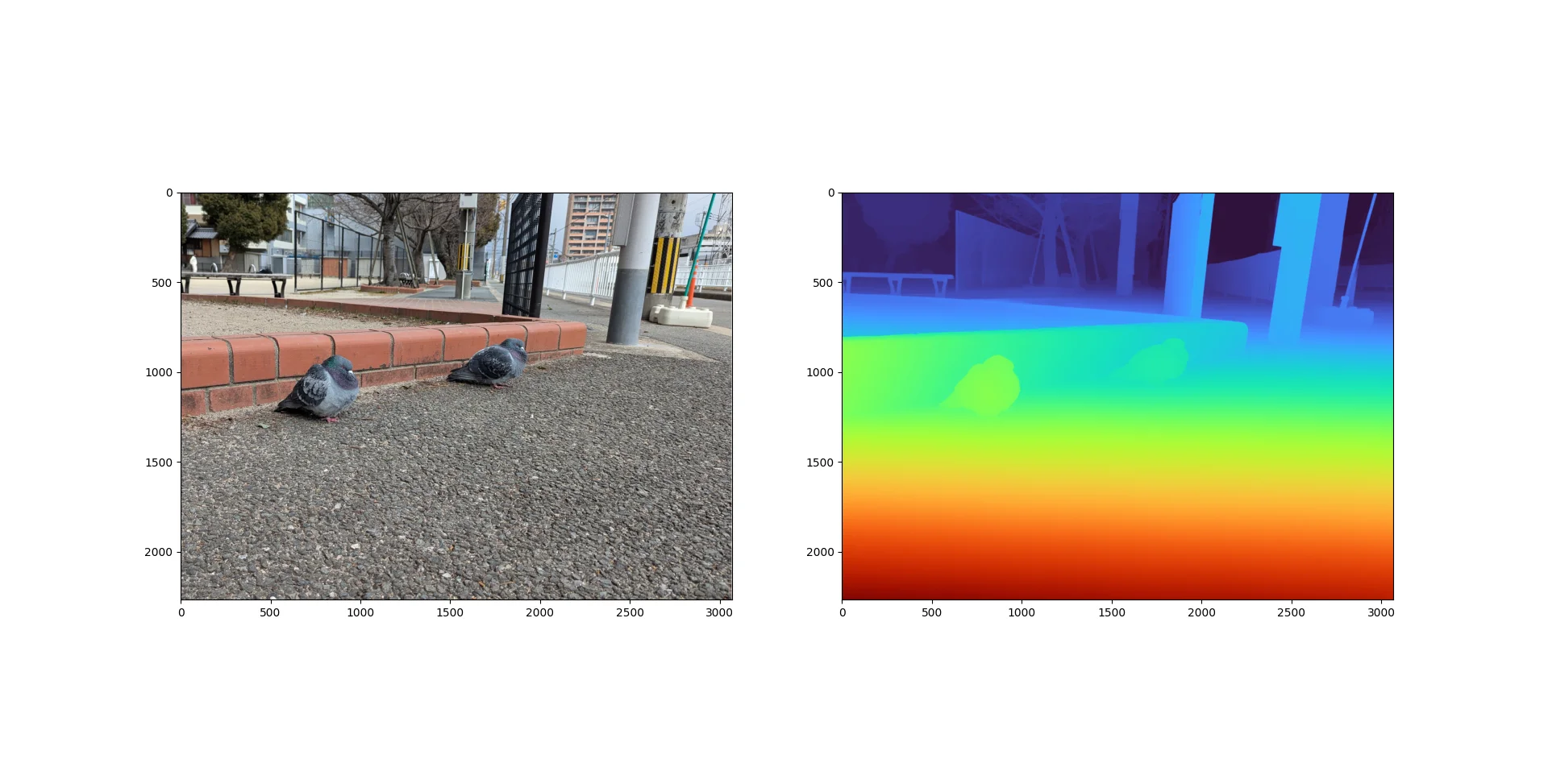
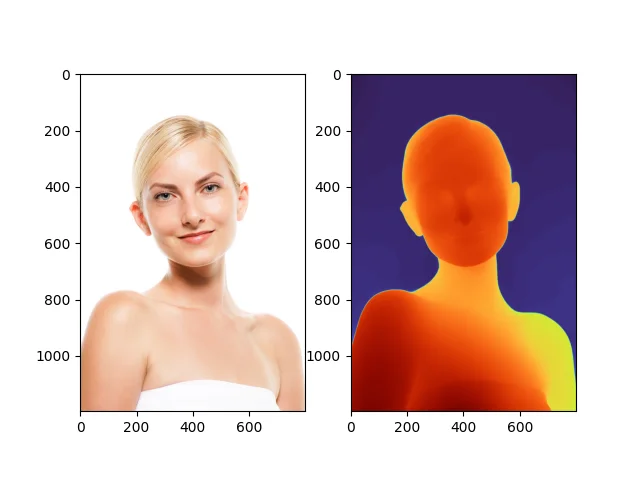
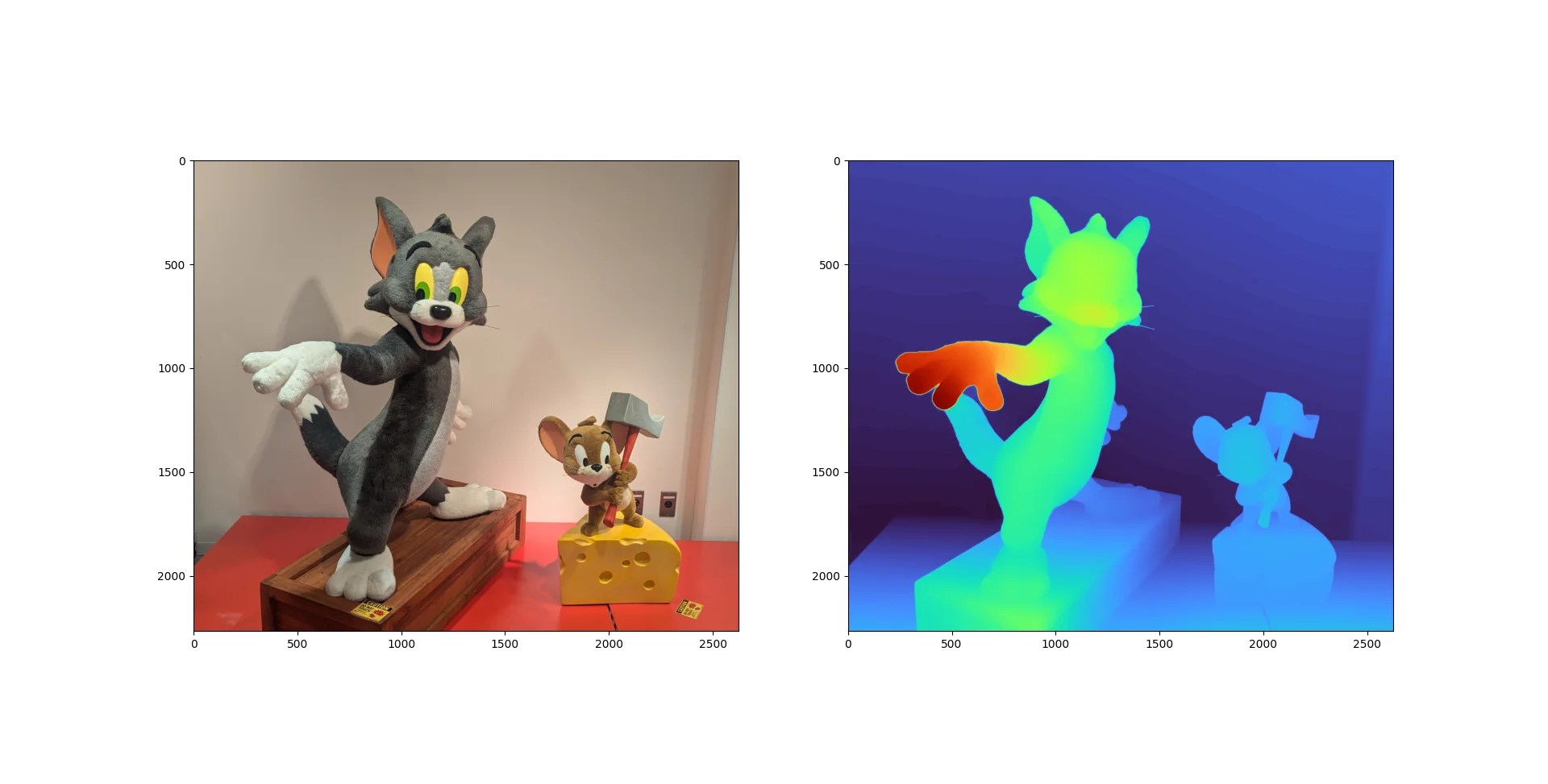
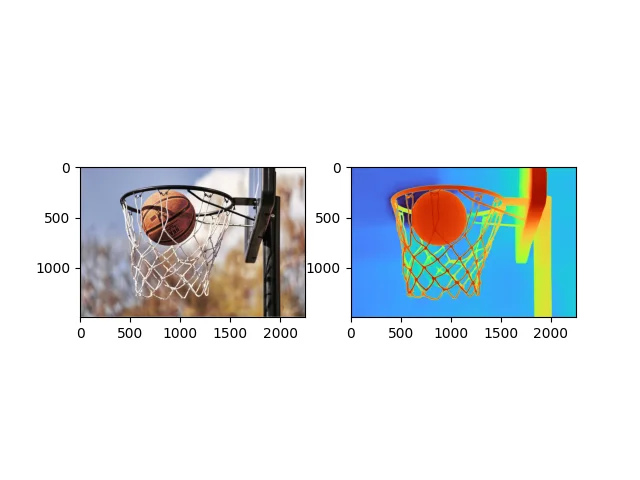
出力速度はどれも大体2秒以下位。
深度マップ正規化の改善
このセクションでは、メトリック深度推定特有の「正規化問題」とその対処法を学びます。正規化手法の選択は、深度マップの可視化品質を大きく左右する重要なテーマです。
正規化の基礎知識
深度マップを画像として可視化するには、深度値(浮動小数点数)を 0--255 の整数値に変換する「正規化」が必要です。メトリック深度推定モデルでは出力値が実距離を反映するため、画像の内容によって値の範囲が大きく異なります。この性質を理解しておかないと、「なぜか画像が真っ黒になる」といった問題に対処できません。
代表的な正規化手法は以下の通りです。
| 手法 | 原理 | 得意な場面 | 弱点 |
|---|---|---|---|
| 線形正規化(Min-Max) | 最小値を0、最大値を255にマッピング | 屋内・深度範囲が狭い画像 | 外れ値(極端に遠いピクセル)に弱い |
| パーセンタイルクリッピング | 上下1%の外れ値を除外してから線形正規化 | 屋外画像(遠景あり) | クリッピング領域は飽和(全白/全黒)になる |
| 対数変換 | 深度値を対数で圧縮してから正規化 | 深度範囲が非常に広いシーン | 立体感が穏やかになりやすい |
| 逆深度変換(1/d) | 深度値の逆数を取ってから正規化 | ポートレート、物撮り | 遠景がほぼ均一になる |
以下、松崎の検証を通じて各手法の実際の効果を確認していきます。
問題: min/max正規化で屋外画像が真っ黒になる
なぜこれが起きるか: Apple Depth Pro はメトリック深度推定モデルであり、出力値は実際の距離(メートル)を表します。屋外画像では空や遠景のピクセルが非常に大きな深度値を持ちます。この状態で単純な min/max 正規化を行うと、例えば手前の被写体(0.5m -- 5m)の値が 0 -- 255 のうちごく僅かな範囲(0 -- 0.1 程度)に圧縮されてしまい、結果として画像がほぼ真っ黒に見えます。
屋外の画像がうまく出力されないのは正規化がうまくいっていないのではないかと考え、最大値と最小値を出力してみました。
powershell
Min depth: 0.56856734
Max depth: 10000.0最大値が10000.0と非常に大きいです。これではmin/max正規化を行うと、手前の被写体の深度値がごく僅かな差に圧縮されてしまい、画像がほぼ真っ黒になってしまいます。
鳩の画像は難しいんだと思います。バスケの画像もものすごく黒く、屋外は苦手なのかもしれません。一見黒く見えてもよく見ると濃淡がついています。
対策1: パーセンタイルクリッピング
ChatGPTに提案されたパーセンタイルによるクリッピングを組み込んでみました。
python
import torch
import numpy as np
from PIL import Image
import depth_pro
def generate_depth_map(input_path, output_path):
# GPUが利用可能な場合はGPUを使用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# モデルとトランスフォームの読み込み
model, transform = depth_pro.create_model_and_transforms()
model = model.to(device)
model.eval()
# 画像の読み込みと前処理
image, _, f_px = depth_pro.load_rgb(input_path)
image = transform(image).unsqueeze(0).to(device)
# 推論の実行
with torch.no_grad():
prediction = model.infer(image, f_px=f_px)
# デプスマップの取得
depth = prediction["depth"].squeeze().cpu().numpy()
# パーセンタイルの値を計算
vmin = np.percentile(depth, 1)
vmax = np.percentile(depth, 99)
# クリッピング
depth_clipped = np.clip(depth, vmin, vmax)
# 正規化
depth_normalized = ((depth_clipped - vmin) / (vmax - vmin + 1e-6) * 255).astype(np.uint8)
# 画像として保存
depth_image = Image.fromarray(depth_normalized)
depth_image.save(output_path)
print("Min depth:", depth.min())
print("Max depth:", depth.max())
print(f"Depth map saved to {output_path}")
if __name__ == "__main__":
input_image_path = "./data/Hato.jpg" # 入力画像のパスを指定
output_image_path = "./depth_map_output.png" # 出力画像のパスを指定
generate_depth_map(input_image_path, output_image_path)出力結果をネガポジ反転させたもの:

いい感じかもしれません。SDSしてLKGで表示させてみました。
背景部分は少し立体感が表現されるようになりましたが、手前が全くでした。背景部分の立体感といっても、ペーパーマリオのような立体感で、きれいさはあまりありません。
ポートレートの画像も同じように出力してみましたが、ほかモデルと比べるとやはり立体感を強くつけるのが苦手なのだなという印象を受けました。
.webp)

対策2: 対数変換
今度は対数変換によるアプローチを試しました。
python
import torch
import numpy as np
from PIL import Image
import depth_pro
def generate_depth_map(input_path, output_path):
# GPUが利用可能な場合はGPUを使用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# モデルとトランスフォームの読み込み
model, transform = depth_pro.create_model_and_transforms()
model = model.to(device)
model.eval()
# 画像の読み込みと前処理
image, _, f_px = depth_pro.load_rgb(input_path)
image = transform(image).unsqueeze(0).to(device)
# 推論の実行
with torch.no_grad():
prediction = model.infer(image, f_px=f_px)
# デプスマップの取得
depth = prediction["depth"].squeeze().cpu().numpy()
# 深度値が0以下にならないようにシフト(1e-6でオーバーフロー防止)
depth_shifted = depth - depth.min() + 1e-6
# 対数変換(自然対数)
depth_log = np.log(depth_shifted)
# 対数変換後の値の範囲を確認してみる
print("Min log depth:", depth_log.min())
print("Max log depth:", depth_log.max())
# 対数変換後に正規化
depth_normalized = ((depth_log - depth_log.min()) / (depth_log.max() - depth_log.min() + 1e-6) * 255).astype(np.uint8)
# 画像として保存
depth_image = Image.fromarray(depth_normalized)
depth_image.save(output_path)
print(f"Depth map saved to {output_path}")
if __name__ == "__main__":
input_image_path = "./data/Model.jpg" # 入力画像のパスを指定
output_image_path = "./depth_map_output.png" # 出力画像のパスを指定
generate_depth_map(input_image_path, output_image_path)ポートレート画像ではあまり立体感がつかなくなりました。パーセンタイルクリッピングの時よりついていません。
しかしハトのほうは上手く深度推定できました。LKGでも背景前景ともにきれいに立体視できました。


結論: 画像によって正規化方法を使い分ける
推定する画像によって深度推定の正規化の仕方を変えた方がよさそうです。
| 正規化手法 | 向いている画像 | 特徴 |
|---|---|---|
| パーセンタイルクリッピング | 屋外画像(遠景あり) | 外れ値を除外し、主要な深度範囲にコントラストを集中させる |
| 対数変換 | 深度範囲が広い屋外シーン | 広いダイナミックレンジを対数的に圧縮し、近景・遠景の両方を表現する |
| 単純min/max | 屋内・深度範囲が狭い画像 | 最もシンプルだが、外れ値に弱い |
補足: 逆深度変換(1/d)について
上記3手法に加えて、逆深度変換(深度値 d を 1/d に変換してから正規化する手法)も有用です。カメラに近い領域により多くのコントラストを割り当てるため、ポートレートや近距離のオブジェクトの微細な凹凸を表現するのに適しています。ただし遠景はほぼ均一な値になるため風景写真には不向きです。
使い分けの指針まとめ:
- 屋内ポートレート、物撮り → 線形正規化 or 逆深度変換
- 屋外シーン(前景が主役) → パーセンタイルクリッピング
- 深度範囲が非常に広いシーン → 対数変換
- 近景の細部を強調したい → 逆深度変換
万能な正規化手法は存在せず、画像の内容と用途に応じて使い分けることが実用上の最善策です。
LKGでの表示
このセクションでは、深度マップをLKGディスプレイで立体表示する手順を学びます。
サイドバイサイド(SDS)画像の作成
深度マップとカラー画像をサイドバイサイド方式で結合します。結合には以下のツールを使用しました。
出力結果をサイドバイサイド方式で結合したもの:




ネガポジ反転の必要性
なぜ反転が必要なのか: 深度マップにおける白黒の意味は、モデルとビューアで異なる場合があります。Apple Depth Pro のデフォルト出力は「近い=小さい値(黒)、遠い=大きい値(白)」です。一方、LKG の RGBD モードは「近い=白、遠い=黒」を期待します。この不一致があると、奥にあるはずの壁が手前に見えてしまうなど、奥行きが反転した表示になります。そのため、白黒反転(ネガポジ反転)が必要です。
Looking Glass Studioにさっき作ったSDS画像をドラッグアンドドロップし、RGBDを選択したところ、奥行きが反転して見えてしまいました。奥にある壁が手前に見えてしまいます。
反転には以下のツールを使用しました:
表示結果
反転後のSDS画像でうまく表示できました。

各画像のLKG表示結果:
- ハト: 黒くなっているところだけ凹んで見えたが他はすべて平面
- バスケゴール: 同上
- ポートレート: 立体感は控えめだが、肩の奥行きがよくわかる
- トムとジェリー: 一番わかりやすく立体視できた




Depth Anything V2との比較
このセクションでは、Apple Depth Pro と Depth Anything V2 の出力品質の違いを、LKG 表示での実際の比較結果から学びます。
比較対象はDepth Anything V2のLargeモデルです。Depthは一定、Focusは適宜調整してあります。
画像別評価
| 画像 | Apple Depth Pro の評価 | Depth Anything V2 との比較 |
|---|---|---|
| トムとジェリー | トムの腹から足にかけてや、尻からしっぽにかけてのなめらかさも十分。何よりボケが少ない。手前に来ている手もあまりぼけなく、しかし手より奥にある顔もきれいに見える。 | 奥行き感はDAV2のほうが強いが、ADPでも充分に描写されている。 |
| ハト | ADPでも充分奥のものは奥にあるんだなと認識はできるが、奥行きのつき方がやはり薄い。その分ぶれにくくて、見やすさはある。 | DAV2の奥行き感が強い。ADPは薄いが見やすい。 |
| バスケゴール | ボード部分が破綻しておらず、穴が開いていない。網もすごくきれいに出力されていて、ほかのモデル(MogeやMarigoldでも)では必ずあったボールだけこちらに出て見えるという現象が起きていない。奥の方の網は奥の方に描写されているし、手前のほうの網は手前のほうに描写されている。バスケボードの裏側も全く破綻がない。すごい。 | ADPはボード破綻なし、網もきれいに出力。ボールだけ前に出る現象なし。 |
| ポートレート | DAV2では眉間や鼻など出っ張りすぎではというところが違和感のないように解消されている。ただ、その分ほほのふくらみはあまり描画できていない。 | DAV2は眉間・鼻が出すぎだがADPは違和感なし。ほほのふくらみ描画は弱い。アジア人向けにはADPが良い。 |
総評と用途別推奨
松崎所感: 総評としては、DepthAnythingのほうはジャンキーな奥行きの付け方をするのに対して、AppleDepthProのほうは丁寧な奥行きの付け方をしている感じがした。マクドナルドとパン屋のサンドイッチ的な差がある。
ので、どちらがすごいとかではなく、好みの問題のような気がする。
LKGを使うにあたって、このモニターの魅力を最大限に生かしたい!というのであればより奥行きのつくDepthAnythingを使った方がよいだろうし、遺影として使ったり、何かリアルに見たいものがあって使うのであればAppleDepthProを使って深度推定したほうがより満足のいくモデルが作れると思う。
松崎の比較検証結果を踏まえた、用途別の推奨をまとめます。
| 用途 | 推奨モデル | 理由 |
|---|---|---|
| LKGで最大限の奥行き表現 | Depth Anything V2 | 奥行きの付け方が強く、LKGディスプレイの立体感を最大限に引き出せる |
| リアルな立体感の再現 | Apple Depth Pro | 丁寧で自然な奥行き表現。違和感のない立体視が可能 |
| 業務用ポートレート | Apple Depth Pro | 眉間・鼻の出っ張りすぎを回避でき、特にアジア人の顔に対して違和感のない結果を得られる |
| 構造物の精密な深度推定 | Apple Depth Pro | バスケゴールの網やボード裏面など、複雑な構造の破綻が少ない |
| 遺影・メモリアル用途 | Apple Depth Pro | 自然な立体感でリアルに見える仕上がりになる |
| インパクト重視の展示 | Depth Anything V2 | 立体感の強さが見た目の印象を高める |
なお、Apple Depth Pro はメトリック深度推定であるため出力値の範囲が画像に依存し、適切な正規化が必要となります。Depth Anything V2 は相対深度推定であるため正規化の手間が少ないという運用面でのメリットもあります。
参考リンク
- GitHub - apple/ml-depth-pro: Depth Pro: Sharp Monocular Metric Depth in Less Than a Second.
- apple/DepthProをローカルで動かす - Qiita
- 画像結合ツール|フォトコンバイン
- 画像の色反転、ネガポジ反転加工 | 無料オンラインソフト
Author: 松崎 | Source:
松崎\AppleDepthPro 1a5aba435ee780d38737f13cbf1fe051.mdAI Enhanced: Claude -- 2026-03-05