Appearance
クラウド深度推定 API
概要
2D動画をAIで深度推定し、Looking Glass 立体表示用の RGBD SBS 動画に変換するクラウドAPIです。Modal(サーバーレスGPU)上にデプロイ済みで、iPad 等あらゆるデバイスから HTTP POST するだけで利用可能です。
何が変わったか:
| Before(従来) | After(クラウドAPI化) | |
|---|---|---|
| 実行環境 | GPU搭載 Windows PC のみ | どのデバイスからでも |
| セットアップ | CUDA + Python 環境構築が必要 | URLにPOSTするだけ |
| 待機コスト | PCの電気代 | ゼロ(使った秒数だけ課金) |
システム構成
┌──────────────┐ HTTPS (POST) ┌──────────────────────────┐
│ │ 動画ファイル送信 │ Modal Cloud (自動起動) │
│ iPad / PC │ ──────────────────────────→ │ │
│ (任意端末) │ │ NVIDIA A10G GPU (24GB) │
│ │ ←────────────────────────── │ Video-Depth-Anything │
│ │ RGBD SBS動画 返却 │ (深度推定AI) │
└──────────────┘ └──────────────────────────┘処理の流れ
- クライアント(iPad等)が動画ファイルをAPIにPOST送信
- Modal がクラウドGPUコンテナを自動起動(未起動時は約30秒のウォームアップ)
- Video-Depth-Anything(VDA-Large)でフレームごとに深度推定
- カラー映像と深度マップを左右に並べた「RGBD SBS形式」のMP4を生成
- 元動画の音声も自動で引き継ぎ
- 完成した動画をレスポンスとして返却
- 2分間リクエストがなければコンテナ自動停止(課金停止)
API エンドポイント(デプロイ済み)
| 用途 | Method | URL |
|---|---|---|
| 深度推定 | POST | https://soichiro-xse--am3d-vda-api-vdainference-infer.modal.run |
| モデル予熱 | POST | https://soichiro-xse--am3d-vda-api-vdainference-warm.modal.run |
| 死活監視 | GET | https://soichiro-xse--am3d-vda-api-health.modal.run |
リクエストパラメータ(/infer)
| パラメータ | 必須 | デフォルト | 説明 |
|---|---|---|---|
file | ✅ | — | 動画ファイル(MP4, AVI, MOV等) |
encoder | vitl | モデルサイズ: vits(小), vitb(中), vitl(大・高品質) | |
depth_type | relative | 深度種別: relative(相対) or metric(メートル) | |
input_size | 518 | 推論解像度(大きいほど高精度・低速) | |
max_res | 1280 | 出力の長辺最大ピクセル | |
target_fps | -1 | 出力FPS(-1 = 元動画と同じ) | |
p_low / p_high | 1.0 / 99.0 | 深度の正規化範囲(外れ値除去) | |
white_near | true | 近い物体を白で表現するか |
レスポンス
- Content-Type:
video/mp4 - ヘッダー:
X-Processing-Time: サーバー側処理時間(秒)X-Job-Id: ジョブ識別子Content-Disposition: ファイル名付きダウンロード
出力形式(RGBD SBS)
┌─────────────────────────────────────┐
│ カラー映像 │ 深度マップ │
│ (そのまま) │ (白=近い 黒=遠い) │
│ │ │
│ ← 左半分 → │ ← 右半分 → │
└─────────────────────────────────────┘- フォーマット: MP4(コーデック mp4v)
- 幅: 出力解像度 × 2(左右が同じ解像度で横並び)
- 深度値: 8bit グレースケール(0〜255)、相対深度
- 音声: 元動画から引き継ぎ(AAC)
AI モデル選定
複数の深度推定AIを検証した結果、Video-Depth-Anything(VDA) を採用しています。
| モデル | 速度 | 品質 | 時間的安定性 | 採用 |
|---|---|---|---|---|
| FlashDepth | 速い | 良い | 不安定(プルプルする) | ✕ |
| Depth-Anything-V2 | とても速い | 良い | 不安定(プルプルする) | ✕ |
| Video-Depth-Anything | 普通 | 非常に良い | 安定 | ✅ |
Looking Glass で表示する場合、フレーム間の深度のブレ(プルプル・歪み)が目立つため、時間的整合性を最優先して VDA を選定しました。事前処理版なので速度はあまり関係ありません。
AI補完
Video-Depth-Anything (VDA) は Depth-Anything-V2 をベースに、動画フレーム間の時間的一貫性(Temporal Consistency)を改善したモデルです。隣接フレーム間の深度マップの整合性を保つ仕組みを持っており、動画再生時の「ちらつき」を大幅に低減します。論文・リポジトリは GitHub - DepthAnything/Video-Depth-Anything で公開されています。
インフラ構成
| 項目 | 仕様 |
|---|---|
| プラットフォーム | Modal(modal.com)— サーバーレスGPUクラウド |
| GPU | NVIDIA A10G(VRAM 24GB) |
| OS | Debian Linux (Python 3.10) |
| フレームワーク | PyTorch 2.1.1 + CUDA 12.1 |
| 動画処理 | OpenCV + FFmpeg |
| モデル保存 | Modal Volume(永続ストレージ) |
| タイムアウト | 1リクエストあたり最大10分 |
| 自動停止 | 2分間アイドルでコンテナ自動停止 |
実測データ
テスト①(2月24日 — 短尺)
| 項目 | 値 |
|---|---|
| 入力動画 | davis_rollercoaster.mp4(1.73MB、数秒) |
| モデルウォームアップ | 51.3秒(うちGPU処理22.8秒) |
| 推論処理 | 39.4秒(うちサーバー処理34.5秒) |
| 出力 | cloud_test_result.mp4(4.19MB、RGBD SBS) |
| 合計コスト | $0.07(約10円) |
テスト②(2月25日 — 実用長)
| 項目 | 値 |
|---|---|
| 動画長 | 約15秒(226フレーム) |
| クラウド処理時間 | 112秒 |
| コスト | 約$0.034(≒5円) |
Modal ダッシュボード実績(2月25日時点)
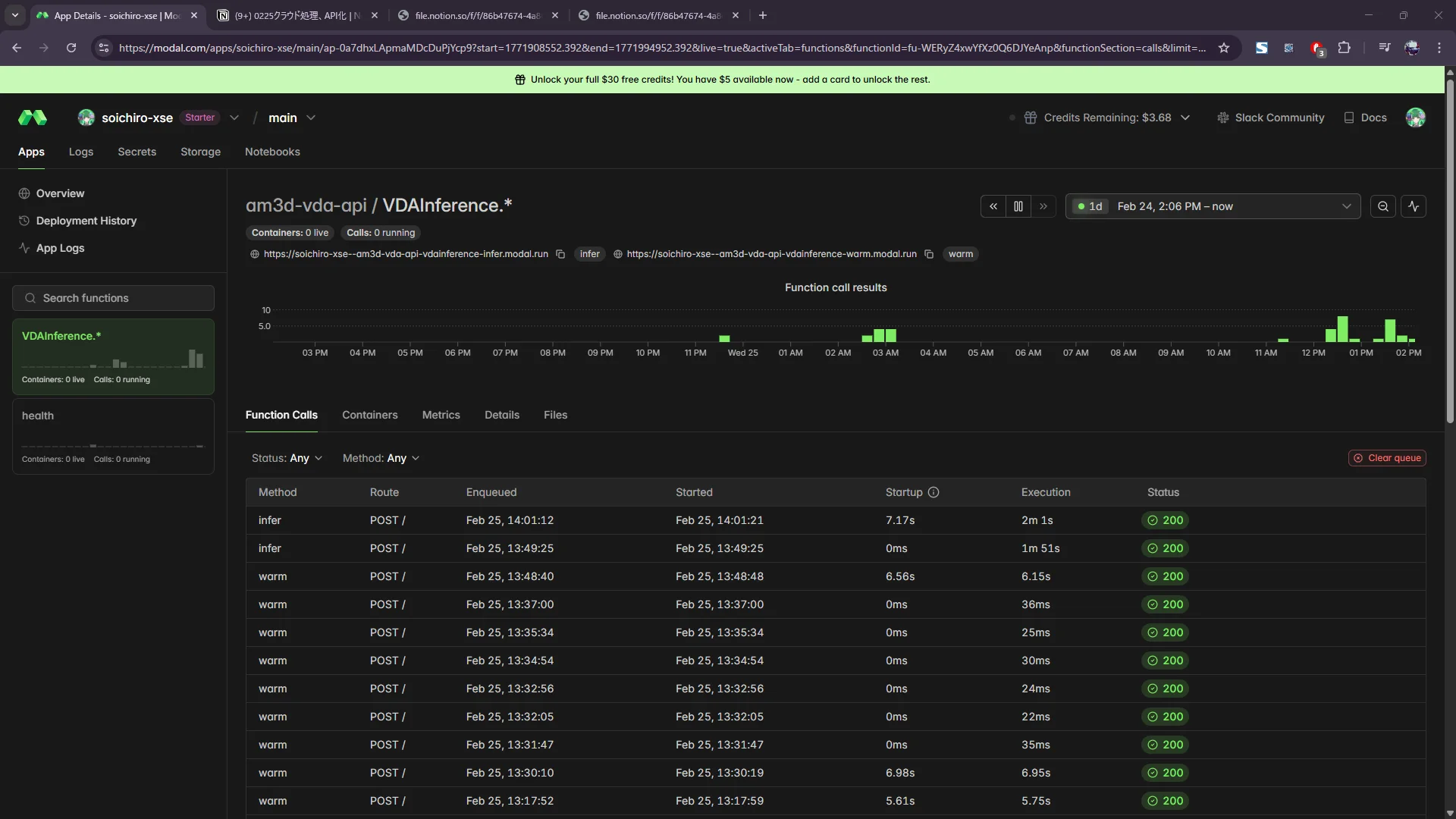
| 項目 | 値 |
|---|---|
| 今月の使用量 | $1.28(約190円) |
| プランの無料枠 | $30/月 |
| 残クレジット | $3.72 |
コスト
| 項目 | 単価 |
|---|---|
| NVIDIA A10G GPU | $0.000306/秒(≒ 165円/時間) |
| 待機中 | $0(ゼロ) |
| 無料枠 | $30/月(Starter プラン) |
詳細なコスト早見表は クラウド処理コスト概算 を参照してください。
運用手順
デプロイ(再デプロイ時)
bash
# プロジェクトフォルダで
.venv\Scripts\activate
modal deploy vda_modal_api.py初回は5〜10分(Docker イメージビルド)。2回目以降は数秒(キャッシュ済み)。
テスト
bash
python test_cloud_api.pyHealth → Warm → Infer の3ステップを自動テストします。
監視
- Modal ダッシュボード: https://modal.com/apps/soichiro-xse/main/deployed/am3d-vda-api
- ヘルスチェック:
GET /healthを定期的に叩けば死活監視が可能
スケーリング
- リクエストが増えれば Modal が自動でコンテナを追加起動(手動設定不要)
- 1コンテナ1リクエスト制(GPU メモリ保護)
- Starter プランで最大10 GPU同時起動、Team プラン($250/月)で50 GPU
停止・削除
bash
# APIを停止(コンテナ削除・課金完全停止)
modal app stop am3d-vda-api
# 再デプロイで復旧
modal deploy vda_modal_api.pyセキュリティ
- エンドポイントはHTTPS
- 現状は認証なし(URLを知っている人は誰でもアクセス可能)
- 必要に応じて Modal の認証機能(Bearer Token)を追加可能
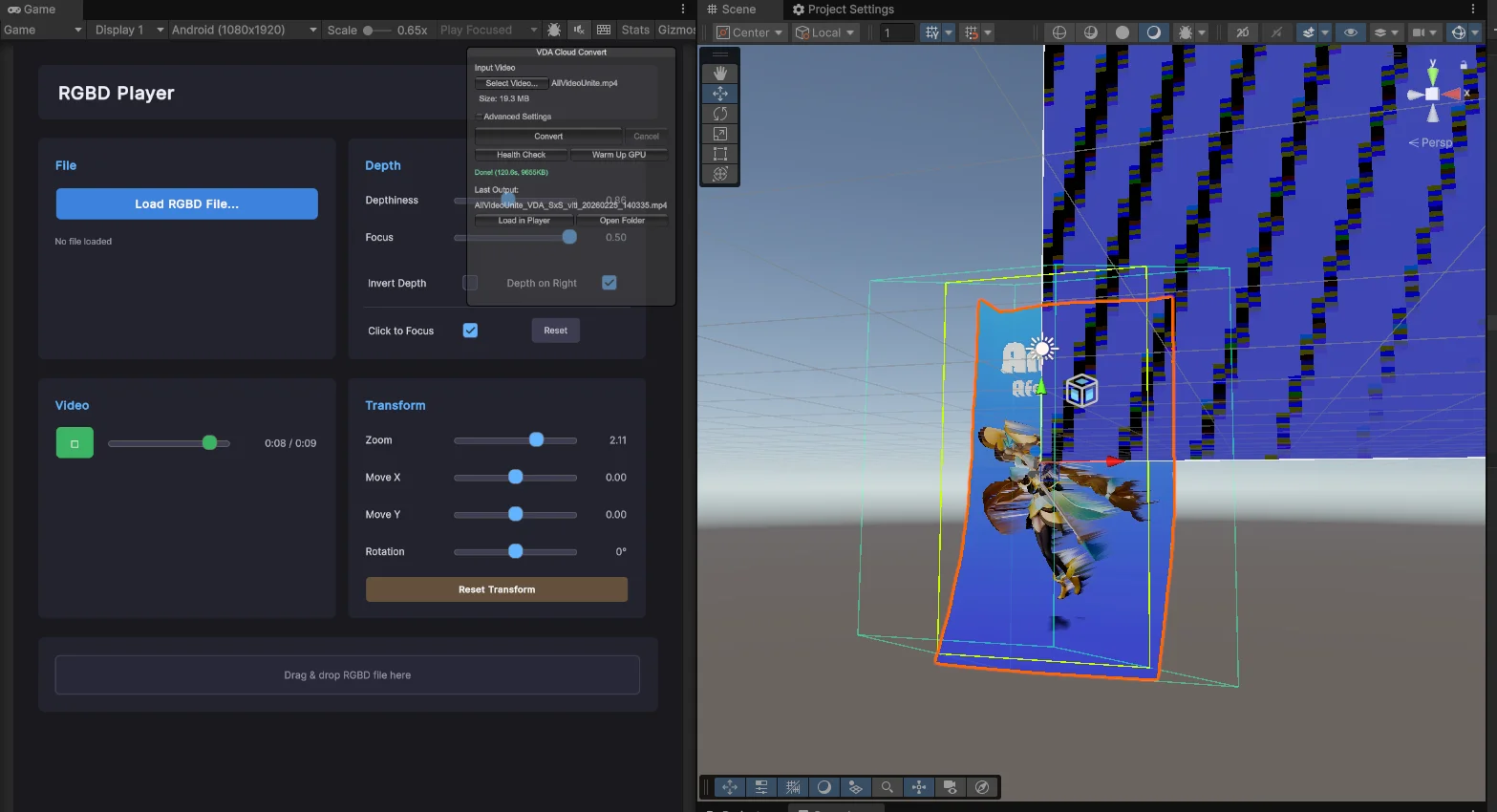
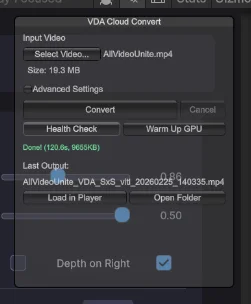
Unity (iPad) クライアント実装例
csharp
IEnumerator ConvertVideo(byte[] videoBytes) {
var form = new WWWForm();
form.AddBinaryData("file", videoBytes, "input.mp4", "video/mp4");
form.AddField("encoder", "vitl");
form.AddField("white_near", "true");
string url = "https://soichiro-xse--am3d-vda-api-vdainference-infer.modal.run";
var request = UnityWebRequest.Post(url, form);
request.timeout = 600;
yield return request.SendWebRequest();
if (request.result == UnityWebRequest.Result.Success) {
byte[] rgbdVideo = request.downloadHandler.data;
// → Looking Glass表示 or ローカル保存
}
}ファイル一覧
| ファイル | 説明 |
|---|---|
vda_modal_api.py | クラウドAPI本体(Modal デプロイ用) |
test_cloud_api.py | APIテストスクリプト |
app/vda_gui_app.py | ローカルGUIアプリ(既存・安定) |
app/rgbd_player_app.py | RGBDプレイヤー(Unity移行予定) |
関連記事
- AM3D 概要 — プロジェクト全体像と検討経緯
- クラウド GPU プロバイダー比較 — Modal 選定の根拠
- クラウド処理コスト概算 — 動画長さ別の詳細コスト表
Author: 山本颯一郎 | Sources: 0224クラウド検証, 0225クラウド処理, AM3D_Cloud_API_Report.md AI Enhanced: Claude — 2026-03-06